The Power of Medical Embeddings
A Medical Code Embedding is a unique data science tool for achieving downstream medical prediction tasks, and derived from the Word2Vec NLP approach.
Embeddings are an early ancestor to transformers - the neural network architecture that sits behind generative AI such as Chat GPT - that have powerful implications for medical event detection and prediction when used on medical code sequences instead of words.

A 3D projection of Tenasol’s medical code embedding, built from millions of medical records.
What is a Medical Embedding?
To understand what a medical embedding is and why we build them, its good to first understand what a word embedding is.
What is a Word Embedding?
When we read a sentence, we interpret what a word is based on the surrounding context. Embeddings were the late 2010’s solution to using this idea in natural language processing (NLP) models, where the meaning of a word (or the vector representing it), was determined by not what it was, but the sequence of words usually around it on average.
Taking this a step further, if all words in the entirety of the english language are quantitatively represented by the contexts in which they normally sit, then synonyms should be represented similarly.
This site shows a word embedding reduced to 3 dimensions in an interactive UI.

Similar words to ‘king‘ are detected as similar to ‘son‘, ‘queen‘, ’thone’, ‘ruler‘, ‘empreror‘, and ‘henry‘. This was a massive breakthrough for the language processing community.

The distance between man and woman, king and queen vectors are distinctively similar in an embedding, but this is just interesting and not very useful.
An embedding itself offers little utility other than maybe finding synonyms or analyzing term relationships. Once defined, the static embedding may be used to support larger deep learning architectures, as words now may be numerically represented with numbers - something a computer can understand. This technique was called “Word2Vec“, and was largely established by Google. Grouping these vectors (words) into lists (sentences) create a 2D matrix, and then feeding these 2D matrices into deep learning enables the additional tasks:
Use Cases of embeddings:
synonym detection
text classification
summarization
named entity recognition
semantic mathematics
Drawbacks of embeddings are that, unlike their next-generation evolution (the transformer, on which ChatGPT is based), embeddings are:
Incapable of interpreting words it has never seen before, whereas transformers can.
Incapable of understand homonyms. For example, our understanding of what a “dog“ is when reading a paragraph are shaped by if it is preceded with “retriever“ (referring to the breed) or “hot“ (referring to the culinary delicacy). Transformers resolve this problem.
Advantages of embeddings:
They require less data and are smaller than transformers in size.
They still are great tools for finding synonyms
Its important to note that no NLP approach is ‘dead‘ per se. All historic NLP approaches offer utility in different situations, and embeddings are no exception. They are fast.
What is a Medical Embedding?
Back to the question. A medical embedding is where we take medical concepts, of which there are millions including LOINC, ICD-10-CM/PCS, and HCPCS among others, and evaluate them in the context in which they occur. For example, by taking millions of medical records at Tenasol, we can find similar concepts that co-occur - technically this is called a co-occurrence embedding as order does not matter. An obvious result of this is that concepts such as “systolic pressure“ and “diastolic pressure“ have nearly identical vector values:

Embedding Project showing that systolic BP (LOINC 8480-6) and diastolic BP (8462-4) have identical vectors when reduced to a 3-dimensional space.
As you’d also expect, left-arm amputations and right-arm amputations are also seen identically.
Use Cases of Medical Code Embeddings
Find similar codes: The direct use of this is that practitioner completing a medical record may select an ICD-10-Code, then may be prompted with similar codes they may have meant to input.
Deep Learning with Medical Embeddings: By converting all codes in a medical record to vectors, especially if dates may be attributed to each code to provide a temporal sequence of codes, then prediction models become quite accurate in forecast periods by creating 2D matrices in the same way we input word sequences as sentences to create text classifiers and entity recognition for a very fancy version of convolutional pattern detection:
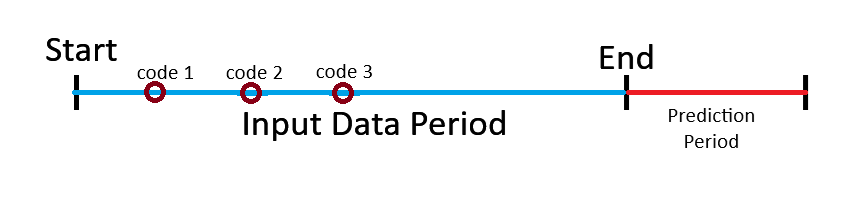
This approach enables:
Potential malpractice detection events that resulted in complications may be be flagged to determine common scenarios where malpractice may have occurred.
Future event prediction - codes may be used as targets to predict such events as hospital readmissions, trips/falls, or more serious medical events in the future, as a function of past sequences.
Gap prediction - sequences of codes grouped together temporally as a pattern can by highly indicative of a medical event that might otherwise not be coded.
… among others.
Extending Medical Embedding to Transformer Tech
The buck may stop here, as sequences of medical codes are far lower in volume than the occurrence of sentences in our ‘data sphere‘. It is hard to believe that at present there is enough data to reliably train a transformer architecture in a similar method to our medical code embedding approach, however it is possible that more dense training methods, or transfer learning methods being researching in the language embedding world may permit this.
Conclusion
Medical code embeddings offer a powerful way to represent clinical concepts numerically, enabling downstream applications such as code prediction, similarity detection, and deep learning-based forecasting. By analyzing millions of medical records, embeddings can identify relationships between codes like LOINC, ICD-10-CM, and HCPCS—even revealing patterns such as the close association between systolic and diastolic blood pressure codes.
While embeddings are not as context-aware as transformer models, they remain highly efficient and effective for tasks that don't require complex language understanding. Their speed and lower data requirements make them ideal for use in clinical decision support systems, coding tools, and machine learning pipelines. At Tenasol, we leverage these embeddings to drive innovations in predictive analytics and medical coding augmentation. As data volumes grow and transformer techniques evolve, the future may see even tighter integration between classic embeddings and modern NLP methods—unlocking new capabilities in healthcare AI and precision medicine.