How to De-identify a Medical Record

HIPAA compliant medical record de-identification NLP is the use of NLP to safely remove protected health information (PHI) and personal identifiable information (PII) from a data asset.
As a regular part of its business, Tenasol performs data extraction and automated medical record de-identification NLP on request. Some initial points about de-identification:
There is a narrow definition of what properly de-identified medical data is according to the The Health Insurance Portability and Accountability Act (HIPAA).
Structured data can be automatically de-identified with NLP. There are a large number of tools (and rules) on how to do this properly, and it may require an expert. When we say ‘structured‘ we mean that the fields are in a database and have typing controls.
Unstructured data cannot reliably be automatically de-identified perfectly (with one exception). While unstructured data (OCR’d images, unconstrained strings of text, etc.) may be manually de-identified by hand, doing it automatically is a categorical impossibility as any model used for removing PHI will do so with less than a 100% accuracy, guaranteeing the presence of PHI. Though you can make data that is structured from unstructured data, then de-identify that.
Penalties for not properly de-identifying data are very high. Therefore medical record de-identification should be taken extremely seriously. HIPAA violations start at 100$ and range to the tens of millions of dollars with possible jail time depending on scale and intent.
PHI/PII vs De-identified vs Synthetic Data
Datasets may be classified into these three categories broadly:
PHI / PII: Real data that contains patient information.
De-identified: Real data that has had identifiable patient information removed or masked
Synthetic: Fake data that is made to imitate patient data in structure and content.
HIPAA De-identification Laws
HIPAA defined two ways to de-identify a data asset:
Narrow, ‘Safe Harbor’ Approach. This states there are 18 identifiers that must be removed. These include patient location, contact information, web URLs, and just about any number/code tied to the patient. Also,
Zips may be retained as the first 3 digits so long as the 3-digit zip has >20,000 residents. HIPAA itemizes these zip codes for those interested.
Dates may only be retained to the year.
Patients older than 90 must be indicated as “90 or older“, and information identifying them as such must be obfuscated, as it over-specifies a small population.
Wider ‘Expert Determination‘ Approach. In this method a person who is an expert (this is undefined) is tasked with determining the correct approach to make sure the data is removed in a specified way from the data, meeting the principles of the safe harbor rules and documenting their approach.
Note: Both categories also prohibit any data that may be joined with public data to de-identify a patient with anything more than low risk. HIPAA is loose about what amounts of ‘low risk’ of identification are.
Tenasol Medical Record De-identification NLP
Rather than performing automated unstructured de-identification, Tenasol uses our data extraction pipeline to pull information from a record, then de-identify the now-structured data, applying the Safe Harbor principle outlined by HIPAA.

Tenasol collects information on data found and classifies it as structured and unstructured. It also determines metadata about entire medical records as a whole. In the following example, we show how a medical finding has elements related to PHI, as well as ones that are no longer of use (like page and coordinates) removed to make a new de-identified finding.
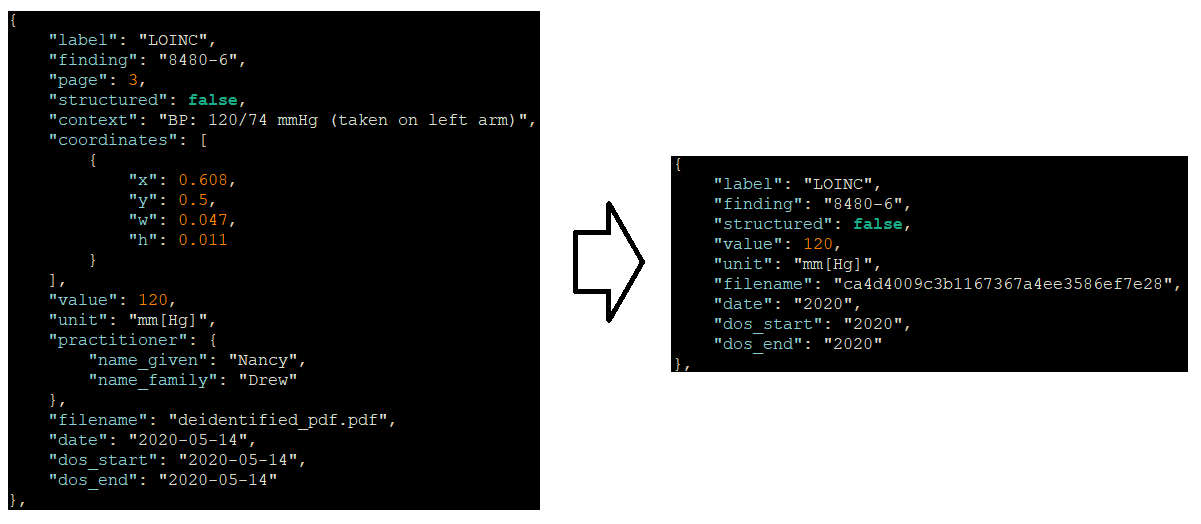
HIPAA compliant medical record deidentification NLP by Tenasol of an individual blood pressure finding with associated metadata.
Medical Record De-identification NLP & Hashing
In many instances, such as the ‘filename’ shown in the above example, it is important to retain a consistent data element but to make sure it is modified in all instances. We want filename to be unique to all found data elements, but we do not want it to be able to be known as it may contain PHI in the form of a patients name.
Hashing is an appropriate way to do this, but it is important to make sure that hashing is done properly. For example if we are SHA256 hashing a persons name and it is ‘John Doe‘ we would get a hash of:
ae6e4d1209f17b460503904fad297b31e9cf6362If someone were to guess John Doe is the patient, they could simply check what the hash is for John Doe, see that they are correct, and the patient is no longer de-identified. To perform a good hash for this scenario:
Use a modern hashing method. SHA1 offers far less encryption than the more common and more secure SHA256.
Cut encryption string down in length. Because a SHA256 hash is so long (64 characters) cutting it down reduces the amount of data that needs to be stored and further prevents decryption.
Add a random value or timestamp when hashing. This prevents the name alone from being hashed to fully encrypt the string.
Taking our example before, the hash would now become a far more secure, more concise string of:
ca4d4009c3b1167367a4ee3586ef7e28Medical Record De-identification NLP Use Cases
Medical record de-identification NLP may be used for a myriad of use cases including:
Clinical Research: Population health research is common with de-identified data sets that describe who is getting what codified treatments, drugs, procedures, or who has what SDoH conditions and what their age and healthcare status is.
Population Health Visualizations: Data that is aggregated and restricted to regions with larger populations may be considered de-identified and publicly shared for use in improving population health decisions and health policy.
Example Data: Example data may be generated for public demonstrations once it has been de-identified using de-identification.
Training of AI models: Models may be trained from this data (with some caveats) to permit deployment on real data that may be used for a variety of use cases that Tenasol also performs.
Other Medical Record De-identification NLP Rules
Note that this is just a summary of a few of the approaches that Tenasol takes and is not the complete picture. Please review HIPAA de-identification rules in detail if you are interested in performing your own medical record de-identification NLP.
Conclusion
Medical record de-identification NLP is crucial for safeguarding patient privacy and maintaining compliance with HIPAA regulations. Tenasol employs a robust approach that integrates structured data extraction and de-identification while adhering to the Safe Harbor principles. By leveraging advanced tools, rules, and metadata analysis, Tenasol ensures accurate and consistent data handling. For sensitive fields like filenames, hashing techniques, such as SHA256 with added random values, provide further protection.
While structured data can be reliably de-identified, unstructured data presents inherent challenges, reinforcing the importance of meticulous extraction and transformation. The penalties for improper de-identification underscore the need for precision and expertise. Tenasol’s pipeline exemplifies a secure, compliant method of de-identification, balancing privacy with functionality. As de-identification is a complex process, organizations must carefully design workflows, consult HIPAA regulations, and, where necessary, seek expert input to achieve the desired low-risk standard of privacy protection.