HEDIS NLP Evidence Detection with Tenasol
HEDIS NLP is the use of NLP for HEDIS / Quality, where plans are rewarded for providing preventative checkups for patients based on their age and gender.
If you are new to HEDIS, see our detailed blog on the subject. If want to learn more about how Tenasol performs our HEDIS evidence extraction stick with us.

Some additional information on HEDIS before starting:
All HEDIS measures are different: Each one permits different data sources to validate or invalidate measure compliance. Measures that permits multiple sources are called “hybrid HEDIS measures“, however these will be retired by NCQA by 2030.
HEDIS is a seasonal operation. Most plans perform HEDIS reviews in the spring, but some seek HEDIS evidence throughout the year as a way of staying ahead of the game.
Both structured and unstructured medical data are useable as evidence. So if you are trying to maximize your HEDIS ratios, you should be using both.
NCQA publishes a directory of permissible evidence codes. These include ICD10CM, LOINC and CPT code among others (blog on coding systems). This is referred to as the HEDIS value sets directory, and links those code groupings to each measure.
HEDIS NLP Processing
HEDIS data can come in the form of HL7 ADT messages, HL7 C-CDA documents, HL7 FHIR, or in unstructured medical record data, all of which are collected via interoperability. As such, Tenasol first uses its multi-modal data extraction pipeline to pull data from those healthcare data sources. Note that Tenasol does not perform HEDIS-specific data extraction in this step, but rather global data extraction that is in a later step reduced to HEDIS-specific evidences:

Example: HEDIS NLP Vitals Extraction
In the below example, we show an instance where Tenasol picks up unstructured vitals and is able to link them to the date of service when it happened.

Example of detection of vitals

Example extraction of a blood pressure using Tenasol HEDIS NLP.
Some additional features that Tenasol performs on extracted data include:
Label/Code representation, like LOINC in the example when we extract them
Standardization of quantity and units to the most common HL7 unit if relevant
Date of the diagnosis or occurrence, if detected
Date of Service if detected, even if it is not on the immediate page
Practitioner detected if present including:
Name
NPI - National Provider Identifier if detected
Phone, if detected
Address, if detected
Page and clustered coordinates If an unstructured finding
Filename indicates the source file, in case multiple files are in the record
Structured Indicator: This is true if the element was in a structured location. It will be False if it is from an unstructured field even if it is an electronic file, or if it is from an unstructured file altogether.
Context information - when unstructured displays surrounding text, and when structured displays the path to the value.
Display (not shown): Describes the description of the code displayed from some structured data types
Status (not shown): Describes the data status for HL7 structured element
Confidence (not shown): present if the finding is a machine learning finding if found with a machine learning model.
Patient (not shown): Tenasol autonomously detects (or takes input override) on who the patient is, attributing this code to them.
Example: HEDIS NLP ML Extraction
Tenasol also uses approximately 100 HEDIS machine learning models to detect both exclusionary and inclusionary evidence. Each machine learning model is for each measure, and for both inclusion and exclusions individually. Below we see those systems detect exclusionary data for BSC (breast cancer screening) as there is demonstrated evidence that the patient has already had breast cancer.

An exclusion detected with Tenasol HEDIS NLP
Example: HEDIS NLP Prioritization
Tenasol also uses the same machine learning models to rank records for HEDIS NLP relevance for clients. For example given a single record each record has a recorded:
Overall priority score, representing how much relevent HEDIS information is contained within
Max priority score, representing the peak HEDIS NLP confidence that evidence was detected
Individual numerator, exclusion, optional exclusion max probability: The independent max probability of that HEDIS NLP classifier picking up evidence across the record. Note that optional exclusions are being retired by NCQA.

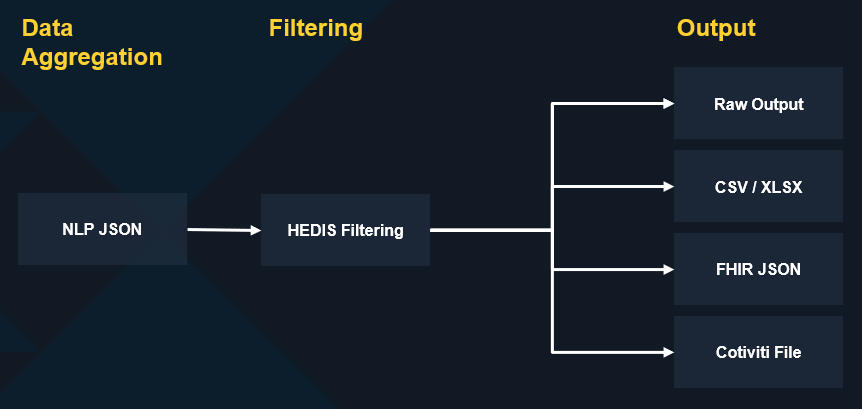
HEDIS NLP Filtering
Once the data is aggregated by Tenasol in a proprietary JSON-based extracted and normalized format, the output data then may be run up against the previously mentioned NCQA HEDIS value sets directory.
The value sets directory used is dependent upon the measurement year, as these permitted evidences change year-to-year. This value set directory roughly looks like this (some columns have been removed for brevity):

NCQA permissible evidences for Cervical Cancer Screening (CCS). These demonstrate that a patient has been treated for the measure and are therefore numerator compliant, barring any exclusion evidence found.
HEDIS NLP Evidence Output Options
In output, Tenasol can:
Run a combination of measures: different measures for different charts or all measure for all charts
Filter out exclusionary evidences for patients falling outside of the demographic, and
Indicate if no evidence was found within a chart.
Output to highlighted PDF for review: Taking in documents, we can highlight information so a person may quickly see where evidences are.
Output to structured format: JSON, CSV, XLSX, FHIR (USCDI or R4), Cotiviti, or other custom formats if requested.
Tenasol-Supported HEDIS Measures
ADD-E Follow-Up Care for Children Prescribed ADHD Medication
AIS-E Adult Immunization Status
APM-E Metabolic Monitoring for Children and Adolescents on Antipsychotics
ASF-E Unhealthy Alcohol Use Screening and Follow-Up
BCS-E Breast Cancer Screening
CIS-E Childhood Immunization Status
COL-E Colorectal Cancer Screening
DMS-E Utilization of the PHQ-9 to Monitor Depression Symptoms for Adolescents and Adults
DRR-E Depression Remission or Response for Adolescents and Adults
DSF-E Depression Screening and Follow-Up for Adolescents and Adults
IMA-E Immunizations for Adolescents
PDS-E Postpartum Depression Screening and Follow-Up
PND-E Prenatal Depression Screening and Follow-Up
PRS-E Prenatal Immunization Status
SNS-E Social Need Screening and Intervention
CCS-E Cervical Cancer Screening
LDM Language Diversity of Membership
BPD Blood Pressure Control for Patients with Diabetes
CBP Controlling High Blood Pressure
CCS Cervical Cancer Screening
CIS Childhood Immunization Status
COA Care for Older Adults
COL Colorectal Cancer Screening
EED Eye Exam for Patients with Diabetes
HBD Hemoglobin A1c Control for Patients with Diabetes
IMA Immunizations for Adolescents
LSC Lead Screening in Children
PPC Prenatal and Postpartum Care
TRC Transitions of Care
WCC Weight Assessment and Counseling for Nutrition and Physical Activity for Children/Adolescents
Conclusion
Tenasol's HEDIS NLP evidence detection offers a comprehensive and efficient solution for healthcare plans aiming to optimize their HEDIS ratios. By leveraging advanced AI and natural language processing techniques, Tenasol can extract and validate evidence from both structured and unstructured data sources, including HL7 ADT messages, C-CDA documents, and unstructured medical records. This multi-modal approach enables the extraction of vital information, such as diagnosis codes, vital signs, and practitioner details, to ensure HEDIS compliance.
Tenasol's use of machine learning models for both inclusionary and exclusionary evidence further enhances the accuracy and relevance of data extraction. These models can rank records based on their relevance to HEDIS measures, ensuring that healthcare plans focus on the most pertinent evidence. Additionally, Tenasol’s integration with NCQA’s HEDIS value sets directory ensures that the extracted data aligns with the most current evidence codes for each measure.
Tenasol offers flexibility for healthcare plans to integrate the results into their existing workflows. Ultimately, Tenasol’s NLP-powered HEDIS solution streamlines evidence extraction, improving the efficiency and effectiveness of HEDIS reviews while reducing manual effort and ensuring accurate compliance with NCQA standards.
Reach out to our team for more information!