What is HL7 C-CDA?

Consolidated Clinical Document Architecture (CCDA) is a narrow, USA-focused implementation of the HL7 third medical data standard - CDA (clinical document architecture). It’s the most dominant structured electronic medical data exchange format at present, though it is not the most recent. It was created to represent patient medical data electronically for informational transfer between facilities. To review other HL7 standards, see our blogs on X12 EDI, HL7 ADT or HL7 FHIR.
Here is a brief outline of what HL7 CCDA is and is not:
HL7 C-CDA files are *.xml or *.json files that contain a number of predefined sections depending on the type of C-CDA message, though the most common is a “summary of care“ C-CDA.
HL7 C-CDA files are not meant for storage. Rather, they are meant for exporting from electronic medical record systems for data transfer to other facilities. Most electronic medical records export to HL7 C-CDA, however they do not natively store files in the format.
HL7 C-CDA exists to represent patient data with more breadth than HL7 ADT. HL7 ADT, while still very present, exists to track patient movements in the healthcare system, however it is not particularly good at wholistically describing a patient. For example, ADT messages rarely contained patient diagnosis or drugs, where as nearly all patient summary C-CDA documents do.
They are NOT human-readable however they allow for free text and html, which assists in making them human readable as they may be run through software to create unstructured PDF representations of an HL7 C-CDA.
They represent a snapshot in time: A single C-CDA is meant to represent a period between a start date, end date, and nearly everything that happened to a patient, however there are other more rare C-CDA types that are not patient summaries.
C-CDA files are NOT entirely structured data: According to our estimates, only about 30% of C-CDA data files are actually structured. This means that data inside of them is usually in unstructured text fields, or within PDFs that are inside the C-CDA. This means that any software that parses them must be able to handle both structured and unstructured data fields, or they are missing a heavy amount of information.
They were not intended for API transfer as HL7 FHIR is: Most commonly, HL7 C-CDA files have been exchanged through SFTP transfers rather than through API messages. However that does not mean it is not possible. C-CDA’s may be wrapped inside of a FHIR message and sent over an API, or they may be binarized and sent over an API however this second method is not standardized.
CDA vs CCDA vs CCD
These terms can definitely be confusing.
CDA (Clinical Data Architecture) is the 3rd edition of HL7 data standards
CCDA (Consolidated Clinical Data Architecture) is the most common implementation of CDA. In other words a version of CDA with more narrowly defined fields for the United States. Other implementations include IPS (International Patient Summary) which is used for cross-border patient data.
CCD (Continuity of Care Document) is a document that summarizes patient care and conforms to the CCDA (and therefore CDA) specification / implementation standard.

Here is what an HL7 CDA file looks like in raw format
C-CDA Stylesheets and Rendering
C-CDA files are difficult for a human to review because of their JSON/XML nature. As a result, a number of tools have been created to do this that either convert the code to HTML or CSS/HTML, sometimes using JavaScript.

Interactive Javascript ONC 2016 C-CDA Rendering Tool Challenge winner [github]
More commonly, C-CDA files are converted to raw html and then converted to a PDF using a “style sheet“, as shown below [ref][ref]. There are many different style sheets available. Note that these style sheets alone will not render all data - advanced tooling is required to extract png/tiff/pdf binaries, as well as to handle zipped CDA files with numerous files present.
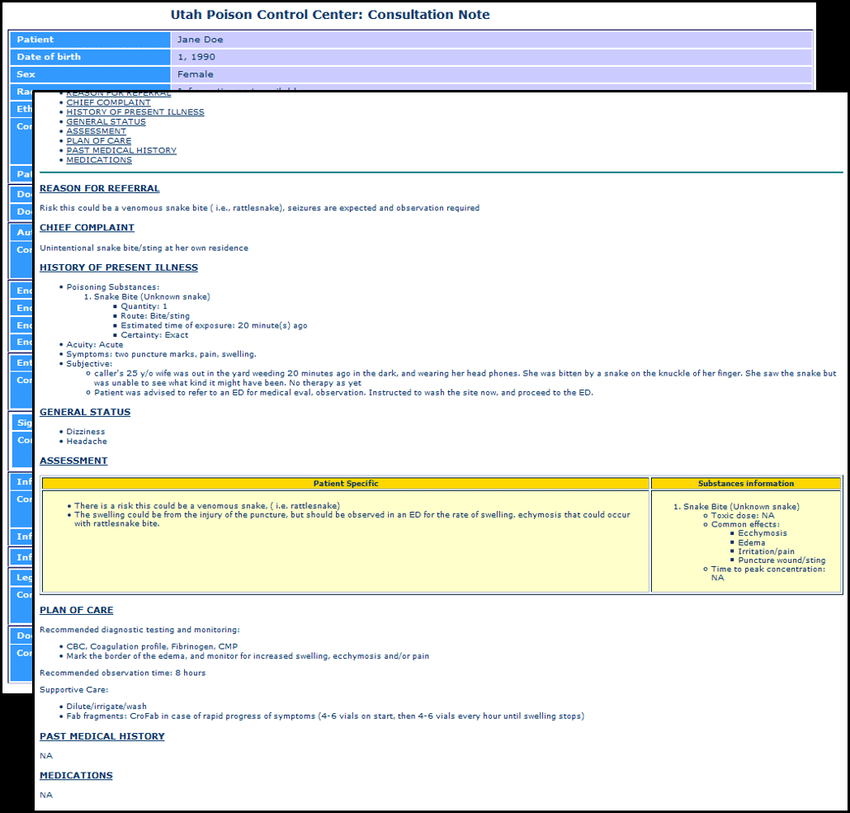
An HL7 CDA after it has been rendered as a human-readable unstructured PDF
HL7 C-CDA Sections
Not all fields are always present in a C-CDA, however the following are the most common ones to find. Each section may have a free text section that can be referenced. Each section also links each piece of data optionally to dates, practitioners, facilities, and occasionally references to other parts of the C-CDA.
Patient Information
Problems
Medications
Allergies, Adverse Reactions, Alerts
Immunizations
Results
Encounters
Procedures
Social History
Plan of Care
Family History
Advance Directives
Functional Status
C-CDA XML & JSON
As mentioned, C-CDA contains both structured and unstructured data. In many cases, the same data that is structured is also represented in an unstructured fashion via HTML to assist in data rendering then the C-CDA is converted to a PDF for human review.

A C-CDA may also contain a binary representation of other files, that can be extracted with special software. Interestingly enough, it is possible for a C-CDA to contain a C-CDA, which contains a C-CDA, which contains a PDF. While it is particularly uncommon for software to be able to parse all of these, Tenasol has proven to do so in its operations.

C-CDA ZIP Structure
C-CDA files may also be represented as a compressed ZIP file. This happens when it has multiple file attachments. In this scenario, there is a '“PackageMetadata.xml” placed in the root directory which describes the facility, practitioner, and date associated with each file attachment.

Parsing an HL7 C-CDA with Tenasol
Few tools exist to process the full breadth of C-CDA files. Bluebutton, also capable of processing HL7 C32 files, is probably the most famous, however it is no longer under active development exists only in JavaScript.
Alternatively Tenasol as a regular part of its business offers C-CDA data extraction of all sections and attached files. When doing so, we not only parse the structured sections, but also the unstructured sections, and pull the linked practitioner and date if present and flatten for any data operations. Tenasol. Some additional features that Tenasol autonomously performs are:
Autonomous patient identification
tracking of where data was found
searching all fields, not just perceived xpaths/jsonpaths where data is expected to occur
machine learning detections with associated confidences

Sample data extraction from a synthetic C-CDA file
Tenasol permits outputting extractions in:
CSV or Excel (.xlsx)
JSON or HL7 FHIR via API
Cotiviti for HEDIS/Quality
…other custom formats if requested
Tenasol is capable of performing narrowed extractions for:
Converting C-CDA to FHIR
See our larger blog on converting medical record file types here.
Converting C-CDA directly to FHIR, the most modern healthcare data format, can be quite tricky to do the substantial differences in data formats. This is further complicated by the multiple implementations of HL7 FHIR (e.g. USCDI and R4 Base to name a few). Despite this, it may be done in one of the following ways:
Wrapping the C-CDA inside of an HL7 FHIR message [no data loss]
Attempting to convert on a best-efforts basis using the HL7 implementation guide or opensource attempts [some data loss]
Extracting key elements and representing them directly with FHIR [some data loss]

A CCDA to FHIR conversion by Tenasol. Different colors represent different resources.
Converting FHIR to C-CDA
See our larger blog on converting medical record file types here.
This task is relatively uncommon as there aren’t many reasons to do it. As a result, the development community has not created any reasonable attempts that are successful in doing so, however a best-efforts attempt with some data loss would be possible if the demand were to appear.
Duplicate Medical Data in HL7 C-CDA Files
Due to the nature of how C-CDA files are created when exported from an EMR, it is more than possible for them to render with duplicate data elements shown multiple times. This has proven problematic for the healthcare industry as medical records can reach lengths on the order of 50,000 pages in rare instances as a result. To learn more about this and how to mitigate the issue, view our blog on medical record deduplication.
Conclusion
HL7 C-CDA is a cornerstone of healthcare data exchange, offering a standardized way to transfer comprehensive patient information between facilities. While its ability to capture both structured and unstructured data ensures versatility, it also introduces complexities in parsing and integration. Tools like Tenasol address these challenges by enabling robust data extraction, deduplication, and conversion to modern standards like HL7 FHIR. Though not designed for storage or real-time API use, C-CDA remains essential for bridging legacy systems and facilitating interoperability. Its role highlights the ongoing need for innovative solutions to streamline healthcare data management and ensure accurate, efficient information sharing.
Reach out to our team to see how you can use your HL7 C-CDA data today!